













皆さんこんにちは。いかがお過ごしでしょうか。
さて、2020年2月にSIGNATEによる機械学習コンペ「国勢調査からの収入予測」が終了しました。
Begineer限定ということもあり、欠損値などがないことから、目標を達成できるのではないかとウキウキしながら取り組みました。
機械学習とはなんぞやという方はぜひこちらをご覧ください。

 Kota
Kota
35歳の医療コンサルタント。とんねるめがほん運営。
9年間医療事務として外来・入院を担当。
毎月約9億円を請求していました。
現在は“医業経営コンサルタント”として活躍中。
投資もそこそこに継続中。米国株を主軸としてETFや不動産も少々投資しています。
趣味は読書・ギター・ドライブ・ダーツ。DJもたまにやります。
Twitterはこちら
今回のテーマ
国勢調査から年収の予測($50,000を超えるか否か)
※本テーマ設定は練習問題に掲載のタスクと同様ですが、データは異なるものを使用しております。
SIGNATE/【第7回_Beginner限定コンペ】国勢調査からの収入予測
https://signate.jp/competitions/413
ということで、SIGNATEから国勢調査から得られたたくさんのデータが与えられます。
その人が「年収が$50,000を超えているか否か」という予測モデルを作成し、その精度を競います。
通常、機械学習コンペで上位入賞(精度の高いモデルを作成)すると賞金や商品がもらえます。
今回はBeginner限定ということもあり、賞金はありません。
また、一定の目標を達成するとBeginnerから昇格することができます。
他者と争うというよりは自分をより高めることに専念するのが目的です。
取り組んでみたこと
ここからはpythonが登場します。
プログラミングに馴染みのない方も、「そういうことやってるのね」程度に思って頂けると嬉しいです。
ライブラリインポート・データ読み込み
必要なライブラリを取得します。
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
import lightgbm as lgb
import sklearn
from optuna.integration import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import MinMaxScaler
from lightgbm import LGBMRegressor
from sklearn.linear_model import LogisticRegression # ロジスティック回帰
from sklearn.neighbors import KNeighborsClassifier # K近傍法
import sklearn.model_selection
import optuna
import optuna.integration.lightgbm as lgb_o
from sklearn.ensemble import AdaBoostClassifier # AdaBoost
from sklearn.svm import SVC # サポートベクターマシン
from sklearn.tree import DecisionTreeClassifier # 決定木データの前処置
与えられたデータについて処理を行いました。
- object型はone hot encordingをして、int型へ変換する
- 年齢・fnlwgt・教育年数などの数値の大きさにバラツキがあるものを正規化
# test・trainを読み込む
train= pd.read_csv("train.csv")
test= pd.read_csv("test.csv")
df_train = pd.DataFrame(train)
df_test = pd.DataFrame(test)
# educationの1st-4thは一つしかないので5ht-6thへ変換
df_train.education = df_train.education.replace("1st-4th","5th-6th")
# object型の値はone hot encording
df_train = pd.get_dummies(df_train, columns=['workclass'])
df_test = pd.get_dummies(df_test, columns=['workclass'])
df_train = pd.get_dummies(df_train, columns=['education'])
df_test = pd.get_dummies(df_test, columns=['education'])
df_train = pd.get_dummies(df_train, columns=['marital-status'])
df_test = pd.get_dummies(df_test, columns=['marital-status'])
df_train = pd.get_dummies(df_train, columns=['occupation'])
df_test = pd.get_dummies(df_test, columns=['occupation'])
df_train = pd.get_dummies(df_train, columns=['relationship'])
df_test = pd.get_dummies(df_test, columns=['relationship'])
df_train = pd.get_dummies(df_train, columns=['race'])
df_test = pd.get_dummies(df_test, columns=['race'])
df_train = pd.get_dummies(df_train, columns=['sex'])
df_test = pd.get_dummies(df_test, columns=['sex'])
df_train = pd.get_dummies(df_train, columns=['native-country'])
df_test = pd.get_dummies(df_test, columns=['native-country'])
# 年齢、fnlwgt、教育年数を正規化
scaler = MinMaxScaler()
df_train[['age', 'fnlwgt', 'education-num']] = scaler.fit_transform(df_train[['age', 'fnlwgt', 'education-num']])
df_test[['age', 'fnlwgt', 'education-num']] = scaler.fit_transform(df_test[['age', 'fnlwgt', 'education-num']])
# trainをx_train y_trainに分割。testからidを除去
x_train = df_train.drop(["Y"], axis=1)
y_train = df_train["Y"]
x_train = x_train.drop(["index"], axis=1)
df_test = df_test.drop(["index"], axis=1)
test = df_test様々な学習モデルで学習して、精度を測る
# 機械学習関連のライブラリ群
import numpy as np
import pandas as pd
import scipy as sp
from scipy import stats
from sklearn.model_selection import cross_val_score # 訓練データとテストデータに分割
from sklearn.metrics import confusion_matrix # 混合行列
from sklearn.linear_model import LinearRegression
from sklearn.decomposition import PCA #主成分分析
from sklearn.linear_model import LogisticRegression # ロジスティック回帰
from sklearn.neighbors import KNeighborsClassifier # K近傍法
from sklearn.svm import SVC # サポートベクターマシン
from sklearn.tree import DecisionTreeClassifier # 決定木
from sklearn.ensemble import RandomForestClassifier # ランダムフォレスト
from sklearn.ensemble import AdaBoostClassifier # AdaBoost
from sklearn.naive_bayes import GaussianNB # ナイーブ・ベイズ
from sklearn.metrics import mean_squared_error
names = ["Logistic Regression", "Nearest Neighbors",
"Linear SVM", "Polynomial SVM", "RBF SVM", "Sigmoid SVM",
"Decision Tree","Random Forest", "AdaBoost", "Naive Bayes"]
classifiers = [
LogisticRegression(),
KNeighborsClassifier(),
SVC(kernel="linear"),
SVC(kernel="poly"),
SVC(kernel="rbf"),
SVC(kernel="sigmoid"),
DecisionTreeClassifier(),
RandomForestClassifier(),
AdaBoostClassifier(),
GaussianNB(),
]X_train, X_test, y_train, y_test = train_test_split(x_train, y_train, test_size=0.2, random_state=100)
result = []
for name, clf in zip(names, classifiers): # 指定した複数の分類機を順番に呼び出す
clf.fit(X_train, y_train) # 学習
score1 = clf.score(X_train, y_train) # 正解率(train)の算出
score2 = clf.score(X_test, y_test) # 正解率(test)の算出
result.append([score1, score2]) # 結果の格納
# test の正解率の大きい順に並べる
df_result = pd.DataFrame(result, columns=['train', 'test'], index=names).sort_values('test', ascending=False)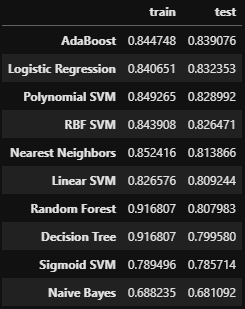
各モデルの値で多数決を取る(アンサンブル学習)
<!-- wp:code -->
<pre class="wp-block-code"><code>"""
AdaBoost
Logistic Regression
Polynomial SVM
RBF SVM
Nearest Neighbors
以上5つのモデルでの正解率が高かった為、これらの学習結果で多数決を取る
"""
# train base model
base_model_1 = AdaBoostClassifier()
base_model_2 = LogisticRegression()
base_model_3 = SVC(kernel="poly")
base_model_4 = SVC(kernel="rbf")
base_model_5 = SVC(kernel="rbf")
base_model_6 = SVC(kernel="sigmoid")
base_model_7 = KNeighborsClassifier()
base_model_8 = RandomForestClassifier()
base_model_9 = DecisionTreeClassifier()
base_model_1.fit(x_train, y_train)
base_model_2.fit(x_train, y_train)
base_model_3.fit(x_train, y_train)
base_model_4.fit(x_train, y_train)
base_model_5.fit(x_train, y_train)
base_model_6.fit(x_train, y_train)
base_model_7.fit(x_train, y_train)
base_model_8.fit(x_train, y_train)
base_model_9.fit(x_train, y_train)
# base predicts
base_pred_1 = base_model_1.predict(test)
base_pred_2 = base_model_2.predict(test)
base_pred_3 = base_model_3.predict(test)
base_pred_4 = base_model_4.predict(test)
base_pred_5 = base_model_5.predict(test)
base_pred_6 = base_model_6.predict(test)
base_pred_7 = base_model_6.predict(test)
base_pred_8 = base_model_6.predict(test)
base_pred_9 = base_model_6.predict(test)</code></pre>
<!-- /wp:code -->
<!-- wp:code -->
<pre class="wp-block-code"><code>sum_pred = base_pred_1 + base_pred_2 + base_pred_3 + base_pred_4 + base_pred_5 + base_pred_6 + base_pred_7 + base_pred_8 + base_pred_9
np.set_printoptions(threshold=np.inf)
sum_pred = np.where(sum_pred >= 8, 1, 0)</code></pre>
<!-- /wp:code -->
<!-- wp:code -->
<pre class="wp-block-code"><code># データの書き出し
submit = pd.DataFrame(sum_pred)
test= pd.read_csv("test.csv")
index = pd.DataFrame(test["index"])
submit = index.join(submit)
submit.to_csv("submit.csv",header=False,index=False)</code></pre>
<!-- /wp:code -->単純なグリッドサーチ
from sklearn.svm import SVC
X_train, X_test, y_train, y_test = train_test_split(x_train, y_train, random_state=0)
param_list = [0.001, 0.01, 0.1, 1, 10, 100]
best_score = 0
best_parameters = {}
for gamma in param_list:
for C in param_list:
svm = SVC(gamma=gamma, C=C)
svm.fit(X_train, y_train)
score = svm.score(X_test, y_test)
# 最も良いスコアのパラメータとスコアを更新
if score > best_score:
best_score = score
best_parameters = {'gamma' : gamma, 'C' : C}
print('Best score: {}'.format(best_score))
print('Best parameters: {}'.format(best_parameters))LightGBMとOptunaでベストパラメータを探る
import optuna.integration.lightgbm as lgb_o
from sklearn.model_selection import train_test_split
import sklearn.datasets
from sklearn.metrics import r2_score
# scikit-learnのtrain_test_splitでデータの準備
X_trainval, X_test, y_trainval, y_test = train_test_split(x_train, y_train, test_size=0.2, random_state=100)
X_train, X_val, y_train, y_val = train_test_split(X_trainval, y_trainval, random_state=0)
# LightGBM用のデータセットに変換
train = lgb_o.Dataset(X_train, y_train)
val = lgb_o.Dataset(X_val, y_val)
# ハイパーパラメータサーチ&モデル構築
params = {'objective': 'regression',
'metric': 'rmse',
'random_seed':0}
gbm_o = lgb_o.train(params,
train,
valid_sets=val,
early_stopping_rounds=300,
verbose_eval=200,)
# 調整後モデルで予測の実行
y_trainval_pred = gbm_o.predict(X_trainval,num_iteration=gbm_o.best_iteration)
y_test_pred = gbm_o.predict(X_test,num_iteration=gbm_o.best_iteration)
# ベストパラメータの取得
best_params = gbm_o.params
print(" Params: ")
for key, value in best_params.items():
print(" {}: {}".format(key, value))
# 評価スコアの計算
r2_trainval = r2_score(y_trainval, y_trainval_pred)
r2_test = r2_score(y_test, y_test_pred)
print("r2_train:{0:.4}".format(r2_trainval))
print("r2_test:{0:.4}".format(r2_test))optunaでランダムフォレストのパラメータを探る
import sklearn.ensemble
import sklearn.model_selection
import optuna
#目的関数の定義
def objective(trial):
#ハイパーパラメータの定義
n_estimators = trial.suggest_int('n_estimators', 2, 20)
max_depth = trial.suggest_int('max_depth', 1, 100)
min_samples_split = trial.suggest_int('min_samples_split', 1, 30)
min_samples_leaf = trial.suggest_int('min_samples_leaf', 1, 30)
max_features = trial.suggest_int('max_features', 1, 30)
max_leaf_nodes = trial.suggest_int('max_leaf_nodes', 1, 30)
#ランダムフォレストモデルの作成
clf = sklearn.ensemble.RandomForestClassifier(n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
max_features=max_features,
max_leaf_nodes=max_leaf_nodes,
bootstrap=True,
class_weight=None,
criterion='gini',
min_weight_fraction_leaf=0.0,
n_jobs=1,
oob_score=False,
verbose=0,
warm_start=False)
#ランダムフォレストモデルを交差検証してその平均スコアを返す
return sklearn.model_selection.cross_val_score(clf, x_train, y_train, n_jobs=-1, cv=3).mean()
#Optunaオブジェクトの作成 directionをmaximizeとすることで最大化
study = optuna.create_study(direction='maximize')
#500回の試行で最適化をおこなう。
study.optimize(objective, n_trials=500)
#trialにベストのトライアル結果を入れる。
trial = study.best_trial
#ベストな結果、パラメータの表示
print('Accuracy: {}'.format(trial.value))
print("Best hyperparameters: {}".format(trial.params))結果
残念ながら目標の精度(0.844)に達することができませんでした。


今回は0.8429412ということで残り0.0010588足りませんでした。
めっちゃ惜しい!!!
良かった点・反省点
良かった点
初めてアンサンブル学習に取り組むことができました。
(結果的に精度の向上にはつながりませんでしたが、、笑)
反省点
与えられたデータについて新しい情報を加えることができませんでした。
ここまで読んでいただきありがとうございました!

