













皆さんこんにちは。
G検定の資格試験のために勉強真っ最中の方へ送ります。
G検定とは「一般社団法人日本ディープラーニング協会」による検定であり、ディープラーニングについてどれだけ知っているかを測るものです。
詳しくはこちらをご覧ください。
https://www.jdla.org/certificate/general/
(一般社団法人日本ディープラーニング協会/G検定とは)
受験については自宅でオンライン試験となります。
(つまりは、カンペが大活躍するのです。)
もちろんカンペを作ったからといって必ず合格するとは限りませんが、大いに役立つことでしょう。(なにせ問題量が非常に多いので。。。)
ということで以下はG検定のためのカンペとなります。
G検定のシラバスには以下の大きなグループ分けがされています。
- 人工知能(AI)とは(人工知能の定義)
- 人工知能をめぐる動向
- 人工知能分野の問題
- 機械学習の具体的手法
- ディープラーニングの概要
- ディープラーニングの手法
- ディープラーニングの研究分野
- ディープラーニングの応用に向けて
シラバスに沿って作成しております。
必要な方は是非ご活用ください。
★人工知能(AI)とは(人工知能の定義)★
「人工知能( Artificial Intelligence)」1956年にアメリカで開催されたダートマス会議でジョン・マッカーシーが初めて使った言葉
人工知能とは何かについては専門家の中でも共通した定義はない。(「人間と同じ知的な処理能力」が研究者によって異なるから)
- 「人工的につくられた人間のような知能、ないしはそれをつくる技術」by松尾豊
- 「明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野」byアーサー・サミュエル
- 「人工的につくられた、知能を持つ実体。あるいはそれをつくろうとすることによって知能自体を研究する分野である」by中島秀之氏(公立はこだて未来大学)
- 「計算機知能のうちで、人間が直接・間接に設計する場合を人工知能と呼んでよいのではないかと思う」by山川宏氏(ドワンゴ人工知能研究所所長)
人口知能のレベル別分類
| レベル1 | シンプルな制御プログラム。ルールベース。すべての振る舞いが予め決められている。(エアコン・洗濯機・髭剃り) |
| レベル2 | 古典的な人工知能。探索・推論を行う。状況に応じて複雑な振る舞いをする。知識データを利用する。(株価予想・ルンバ) |
| レベル3 | 機械学習を取り入れた人工知能。多くのサンプルデータから入力・出力関係を学習する。(GoogleMap・Google検索・交通渋滞予測) |
| レベル4 | ディープラーニング。特徴量(どのような特徴が学習結果に大きく影響するか)による学習を行う。(画像認識・土地価格予想・音声認識・自動翻訳) |
AI効果
AIで新しいことが実現されて、原理がわかってしまうと「単純な自動化であって知能とは関係ない」と結論付ける心理的効果
AIとロボットの違い
AI=ロボットの脳に当たる部分
将棋や囲碁は物理的身体は必要ない
AIの研究とは「考える」という「目に見えないもの」を中心に扱う学問
人工知能研究の歴史
- 1946年:ペンシルバニア大学でENIAC(エニアック)巨大電算機が開発。世界初の汎用電子式コンピュータ。
- 1956年:ダートマス会議。マーヴィン・ミンスキー、ジョン・マッカーシー、アレン・ニューウェル、ハーバード・サイモン.などの研究者が参加。ニューウェルとサイモンはロジック・セオリストをデモンストレーションした。
1950年~1960年:第1次AIブーム(推論・探索の時代)
コンピュータが特定の問題に対して解を提示できるようになった。
トイ・プロブレム:迷路や数学の定理の証明のような簡単な問題
トイ・プロブレムは解けても複雑な現実問題は解けないことからブームが覚め、1970年代には冬の時代に
1980年代:第2次AIブーム(知識の時代)
データベースに大量の知識を溜め込んだエキスパートシステムがたくさん作られた。ナレッジエンジニアが必要とされた。
ナレッジエンジニア:人工知能(AI)を応用したシステム構築を専門とする技術者(エンジニア)のことである。
日本では「第五世代コンピュータ」と名付けられたプロジェクトが推進されたが、知識の蓄積・管理が大変になり、1995年から冬の時代へ
知識表現(オントロジー)の研究
2010年~:第3次AIブーム(機械学習・特徴表現学習の時代)
ビッグデータを用いることで人工知能が自ら知識を獲得する機械学習が実用化
知識を定義する要素(特徴量)を人工知能自らが習得するディープラーニング(深層学習)が登場
AlphaGo(アルファ碁):2016年に韓国のプロ棋士に勝利
画像認識競技:ILSVRC(Imagenet Large Scale Visual Recognition Challenge)
| 内容 | |
|---|---|
| アーサー・サミュエル | 機械学習を「明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野」と定義した |
| アラン・チューリング | 人工知能の判定テストであるチューリングテストを考案した |
| アレン・ニューウェル ハーバード・サイモン | 世界初の人工知能プログラムであるロジック・セオリストを開発した |
| アンドリュー・ン | 機械学習などの講義が見れるサイトCourseraの設立に携わった |
| イアン・グッドフェロー | GANを考案 |
| ジェフリー・ヒントン | ILSVRC2012でディープラーニングを使って優勝した Googleに招かれた |
| ジョゼフ・ワイゼンバウム | 世界初のチャットボット、ELIZAを制作した |
| ジョン・サール | 強いAI・弱いAIという言葉を作った |
| ジョン・マッカーシー | 人工知能という言葉を初めて使用した フレーム問題を提唱した |
| スティーブン・ハルナッド | シンボルグラウンディング問題を提唱した |
| ダニエル・デネット | フレーム問題を考えすぎるロボットの例で説明した |
| ヤン・ルカン | GANを「機械学習において、この10年間で最も面白いアイデア」と形容した Facebookに招かれる 有名なCNNのモデルLeNetを考案 |
| ヨシュア・ベンジオ | ディープラーニングの父と呼ばれる 観測データの良い表現について提言した モントリオール大に所属 |
シンギュラリティ(技術的特異点):レイ・カーツワイルなど以下の人物らにより懸念
★人工知能をめぐる動向★
探索・推論
迷路(探索木):場合分けを続けていつか目的の条件に合致するものが出現するという考え方が基礎
幅優先探索:最短距離でゴールにたどり着く解を見つける。すべて記憶しておかなければならないため、メモリ不足になる可能性がある。
深さ優先探索:解が見つかったとしても最短距離であるかどうかはわからない。メモリはあまり必要ない。運が悪ければ時間がかかる
ハノイの塔
ロボットの行動計画
プランニングと呼ばれる技術
掃除するロボット
あらゆる状態(前提条件)について行動と結果を記述しておけば目標とする状態に至る行動計画を立てることができる
STRIPS( Stanford Research Institute Problem Solver):「前提条件・行動・結果」の3つの組み合わせで記述
SHRDLU:1970年にスタンフォード大学のテリー・ウィノグラードによって開発されたシステム。英語による指示を受け付け、積み木の世界に存在する物体(ブロック・四角錘・立方体など)を動かす。
Cyc(サイク)プロジェクトにも引き継がれる
テリー・ウィノグラードはラリー・ペイジ(Google創業者の1人)を育てている
ボードゲーム
2016年3月9日、韓国のプロ棋士にディープマインド社開発のAlphaGo(アルファ碁)が4勝1敗と大きく勝ち越した
- オセロの組み合わせ:約10の60乗通り
- チェスの組み合わせ:約10の120乗通り
- 将棋の組み合わせ:約10の220乗通り
- 囲碁の組み合わせ:約10の360乗通り
コスト
あらかじめ知っている知識や経験を利用してコストを計算することができれば、コストがかかりすぎる探索を省略できる。
ここでの知識をヒューリスティック知識
ヒューリスティック:経験的な・発見的な。。。ここでは「探索を効率化するのに有効な」
Mini-Max法
自分が指す時にスコアが最大となるように、相手が指す時にスコアが最小になるように戦略を立てる
想定される最大の損害が最小になるように決断を行う戦略
Mini-Max法による探索をできるだけ減らす手法→αβ法
最大スコアを選択する過程でスコアが小さいノードが出たら探索を端折る:βカット
最小スコアを選択する過程でスコアが大きいノードが出たら探索を端折る:αカット
モンテカルロ法
コンピューターが仮想的なプレイヤーを演じて完全にランダムに手を指し続け、シミュレーションしてゲームを終局させる方法。
プレイアウト:ゲームを終局させること
プレイアウトを複数回実行するとどの方法が一番勝率が高いかを計算でき、スコアを評価することができる。
数多く打って最良のものを選ぶという評価方法の方が優れている
しかし人間の思考方法とは違ってブルートフォース(力任せ)で押し切る方法であり、探索しなければならない組み合わせが多くなると立ち行かなくなる。
9×9の囲碁ではプロ棋士並みになったが、19×19の囲碁ではプロには勝てない状況が続いた。→ディープラーニングの技術で19×19の囲碁で勝利できた
知識表現
人工無能:チャットボット・おしゃべりボットなどと呼ばれるコンピュータープログラム
ELIZA(イライザ)
人工無能の元祖。1964~1966年にジョセフ・ワイゼンバウムによって開発。
相手の発言をあらかじめ用意されたパターンと比較し、合致した発言があればそれに応じた返答をする。
「オウム返し」が基本で理解しているわけではない。
イライザの成功は音声対話システム・心理療法などに影響を与えている。
エキスパートシステム
ある専門分野の知識を取り込み、その分野の専門家のように振る舞うプログラム
MYCIN(マイシン)1970年代にスタンフォード大学で開発された。
血液中のバクテリアの診断支援。500ルールが用意されており質問に答えていくと感染菌を特定し、対応した抗生物質を処方できる。
69%で正しい処方をすることができる。感染専門医は80%。専門医ではない医師よりは高い。
DENDRAL:1960年代にスタンダード大学で開発された。
未知の有機化合物を特定する。質量分析法で分析
質量分析法:分子をイオン化し、そのm/zを測定することによってイオンや分子の質量を測定する分析法
専門家がもつ知識は豊富であるほど暗黙的であるため、自発的に述べるのは不可能。
インタビューシステムの研究もされた。
一貫していないものを出現し、知識ベースを保守するのが困難となった。
意味ネットワーク
もともとは認知心理学における長期記憶の構造モデルとして考案された
概念をラベルの付いたノードで表し、概念間の関係をラベルの付いたリンクで結んだネットワーク
「is-a」関係
継承関係を表す。
ex)「動物は生物」(動物:下位概念 生物:上位概念)「哺乳類は動物」
推移律が成立する。
ジャンケンは推移律は成り立たない。
→関係によっては成立するものとしないものがある。
「part-of」
属性を表す。
ex)「目は頭部の一部」「肉球は足の一部」
いろいろな関係がある
「指 part of 太郎」「太郎 part of 野球部」⇒「指 part of 野球部」・・・!?
→関係によっては成立するものとしないものがある。
Cyc(サイク)プロジェクト
「すべての一般常識をコンピュータに取り込もう」というプロジェクト
1984年からダグラス・レナートによってスタートした。現在も継続中
オントロジー(ontology)
知識共有は難しい→知識を体系化する方法論が研究→オントロジー研究に繋がった
オントロジー:存在論(存在に関する体系的理論)
「概念化の明示的な仕様」とトム・グルーパーは定義した
オントロジーの目的:知識の共有と活用
オントロジーにおいて「is-a」関係と「part-of」関係は重要
ヘビーウェイトオントロジー(重量オントロジー)
構成要素や意味的関係の正当性について哲学的な考察が必要であり、時間とコストがかかる
ライトウェイトオントロジー(軽量オントロジー)
完全に正しいものでなくても使えるものであればいいという考えから、ウェブマイニング・データマイニングで利用されている。
セマンティックWeb、LOD(Linked Open Data)などの研究で展開されている
ワトソン
IBMが開発した
2011年にアメリカのクイズ番組で歴代人間チャンピオンに勝利。
ライトウェイトオントロジーを生成して、解答に使用した。
質問に含まれるキーワードと関連しそうな解答を高速に検索しているだけ。
現在はコールセンター、人材マッチング、広告など幅広く活用されている。
東ロボくん
東大入試合格を目指す人工知能
2011年にスタート。2016年まで継続された。
2016年6月にはほとんどの私大で合格できるレベルに達したが、質問の意味を理解しているわけではないので読解力に問題がある。
2016年に開発が凍結。
機械学習
人工知能のプログラム自身が学習する仕組み
サンプルデータが多いほど望ましい学習結果が得られる
- 1956年:ダートマス会議
- 1967年:k-平均法
- 1975年:遺伝的アルゴリズム
- 1990年:世界初のWebページ
- 1992年:非線形サポートベクターマシン
- 1998年:Googleの検索エンジン
- 2011年:IBMワトソンがジョバディーで優勝
レコメンデーションエンジン
ユーザーの好みを推測するアプリケーション
スパムフィルター
迷惑メールを検出するアプリケーション
統計的自然言語処理
統計的自然言語処理を使った翻訳では複数の単語をひとまとまりにした単位で最も正解である確率が高い訳を選択する。
「bank」:銀行・土手という意味があるが対話データ(コーパス)がたくさんあれば「銀行」もしくは「土手」と適切な訳に変換する。
ニューラルネットワーク
機械学習の一つで、人間の神経回路を真似することで学習を実現しようとするもの
1958年にフランク・ローゼンブラットが考案した「単純パーセプトロン」が元祖
深層学習(ディープラーニング)
ニューラルネットワークを多層にしたもの
- 1958年:パーセプトロン
- 1969年:パーセプトロンの性質と限界に関する論文
- 1986年:バックプロパゲーション
- 2006年:自己符号化器
- 2012年:ILSVRCでトロント大学(ジェフリー・ヒントンが中心)のSuperVisionが優勝
バックプロパゲーション(誤差逆伝播学習法)
ニューラルネットワークの学習におけるアルゴリズム。1986年にデビッド・ラメルハートらによって命名された。
バックプロパゲーションの役割はコンピュータの回答が誤っていたり、期待と離れている場合、誤差を出力層から入力層へ逆方向に返し、各ニューロンの誤りを正す。
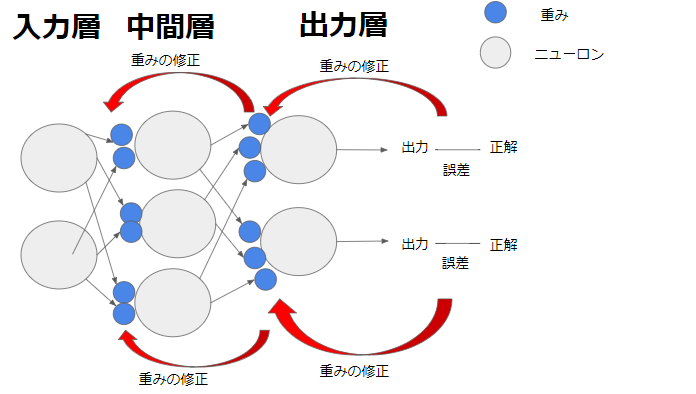
/ 今さら聞けないバックプロパゲーションとはより
注意点は4層以上のバックプロパゲーションはうまくいかないということ。
一般的に層が深くなればなるほど、バックプロパゲーションが下の方まで届かなくなり、学習の精度が下っていくと言われている。
そのため層を増やしすぎない適切な仕組みが必要。
★人工知能分野の問題★
トイプロブレム
コンピューターで扱えるように本質を損なわない程度に簡略化したもの
フレーム問題
1969年にジョン・マッカーシーとパトリック・ヘイズが提唱した問題
今しようとしていることに関係のある事柄だけを選び出すことは実は非常に難しい
洞窟の中に向かうロボットの話
弱いAI、強いAI
1980年にジョン・サールが発表した「Minds,Brains and Programs(脳、心、プログラム)」という論文の中で提示した区分
強いAI
適切にプログラムされたコンピュータは人間と同じ意味で心を持つ。また、プログラム自身が人間の認知の説明である。
弱いAI
コンピュータは有用な道具であればよい。
ジョン・サールは「弱いAI」は実現可能でも「強いAI」は実現不可能と主張
中国語の部屋
身体性
身体が不可欠であるという考え方
コップを理解するには実際に触ってるみる必要がある
→触ると冷たい・落とすと割れる
シンボルグラウンディング問題
スティーブン・ハルナッドにより議論された「シンボルとその対象がいかにして結びつくか」という問題
シマウマ=シマ+ウマ(シマのあるウマ)
特徴量設計
特徴量の選択は人間が行う。
正しい特徴量を見つけ出すのは一般に非常に難しい。
特徴表現学習:特徴量を機械自身に発見させるアプローチ
ディープラーニングは特徴表現学習を行う機械学習アルゴリズムの1つ
チューリングテスト
アラン・チューリングが提唱
別の場所にいる人間がコンピュータと会話をし、相手がコンピュータだと見抜けなければ、コンピュータに知識があるものとする。
1991年以降にチューリングテストに合格する会話ソフトウェアを目指すローブナーコンテストも開催されている
シンギュラリティ(技術的特異点)
人工知能が十分に賢くなり、自分自身よりも賢い人工知能を作るようになった瞬間、無限に知識の高い存在を作るようになり、超越的な知性が誕生するという仮説
| イーロン・マスク | 自動運転車の会社テスラのCEO 「人工知能にはかなり慎重に取り組む必要がある。結果的に悪魔を呼び出していることになるからだ」と懸念を表明 非営利研究組織OpenAIを設立した |
| ヴァーナー・ヴィンジ | シンギュラリティを「機械が人間の役に立つフリをしなくなること」と定義 |
| オレン・エツィオー二 | 「賢いコンピュータが世界制覇するという終末論的構想は馬鹿げているとしか言いようがありません」と発言 |
| スティーブン・ホーキング | 宇宙物理学者 「完全な人工知能を開発できたらそれは人間の終焉を意味するかもしれない」と発言した |
| ヒューゴ・デ・ガリス | シンギュラリティが21世紀の後半に来ると予想 その時人工知能は人間の一兆の1兆倍の知能を持つと主張 |
| ビル・ゲイツ | マイクロソフトの創業者 人工知能脅威論に同調 |
| レイ・カーツワイル | シンギュラリティーという言葉を提唱した 2045年にシンギュラリティが起きると予想した 2029年に人工知能が人間より賢くなると予想した |
知識獲得のボトルネック
1970年代後半はルールベース機械翻訳
1990年代以降は統計的機械翻訳
最近はディープラーニングを使ったニューラル機械翻訳
「He saw a woman in the garden with telescope」
庭にいるのは男性?女性?
一文を訳すのもの一般常識がなければ訳せない
コンピュータが知識を獲得することの難しさ
★機械学習の具体的手法★
教師あり学習
与えられたデータ(入力)を元にそのデータがどんなパターンになるのかを識別・予測する
ex)過去の売上から将来の売上を予測・与えられた動物の画像が何かを識別
- 回帰問題:連続値を予測する問題
- 分類問題:離散値を予測する問題
線形回帰
統計学における回帰分析の一種。
ラッソ回帰(lasso regression)
直線回帰に正則化項の概念を加えた回帰分析。
最小二乗法の式に正則化項(L1ノルム)を加え、その最小を求めることでモデル関数を発見する。
Lasso:自動的に特徴量の選択が行われる。不要なパラメータを削減できる。
リッジ回帰(ridge regression)
直線回帰に正則化項の概念を加えた回帰分析。
最小二乗法の式に正則化項(L2ノルム)を加え、その最小を求めることでモデル関数を発見する。
Ridge正則化:特徴量選択は行わないが、パラメータのノルムを小さくおさえる。(=過学習をおさえる)
ロジスティックス回帰
重回帰分析により対数オッズを予測し、ロジット変換(正規化)によりクラスに属する確率を求める。
最小化を行う関数として尤度関数(ゆうどかんすう)が用いられる。
シグモイド関数をモデルの出力に使用
与えられたデータが正例(+1)か負例(0)の確率が求まる
たくさんの種類を分類したい場合はソフトマックス関数を使用
ランダムフォレスト
決定木を用いる手法
特徴量をランダムで選び出す
ブートストラップサンプリング:全データではなくランダムに一部データを取り出して学習に使用
アンサンブル学習:複数のモデルで学習させること
バギング:全体から一部のデータを用いて複数のモデルで学習する方法
ブースティング
一部のデータを繰り返し抽出し、複数のモデルを学習させる。
逐次処理のため、ランダムフォレストよりいい精度が得られるが、時間がかかる。
AdaBoost、勾配ブースティング(gradient boosting)、XgBoost
サポートベクターマシン(SVM)
ニューラルネットワーク
教師なし学習
入力データが持つ構造・特徴が対象
ex)ECサイトの売上データからどういった顧客層があるのか認識・入力データの項目間にある関係性を把握
k-means
主成分分析(PCA Principal Component Analysis)
データの取り扱い
評価指標
強化学習
★ディープラーニングの概要★
多層パーセプトロン
ニューラルネットワーク
ディープラーニング
既存のニューラルネットワークにおける問題
ディープラーニングのアプローチ
オートエンコーダ
積層オートエンコーダ
ファインチューニング
深層信念ネットワーク
CPUとGPUとGPGPU
ディープラーニングにおけるデータ量
★ディープラーニングの手法★
活性化関数、学習率の最適化、更なるテクニック、CNN、RNN
深層強化学習、深層生成モデル
★ディープラーニングの研究分野★
画像認識、自然言語処理、音声処理、ロボティクス (強化学習)、マルチモーダル

